
电话咨询
027-87311355 13971151027(微信)

微信咨询

点击保存图片或扫码加微信
或加13971151027微信
或加13971151027微信



公司简介
武汉轻洽网络技术有限公司(简称:轻洽网络)是具有丰富经验和雄厚技术实力的企业,轻洽网络专注于大数据、信息安全及互联网领域产品的开发与研究,自主研发,取得多套软件系统国家知识产权证书,获得“国家高新技术企业”、“科技型企业”、“创新型企业”、“三软企业”、“3A企业信用等级”、“优秀企业”、质量管理体系ISO9001、信息技术服务管理体系ISO20000认证及信息安全管理体系ISO27001等认定,主要从事网站建设、系统开发、APP开发、小程序开发、AI大模型营销软件开发等业务,"以技术为主导,以服务为基本",是我们永远的信念和不断追求的目标,致力于帮助中小型企业做好互联网,做大,做强。
-
2016
年
轻洽始建 -
8+
年
开发经验 -
97+
项
获得各项软著 -
5000+
家
服务客户
服务项目
专业从事软件开发,专注企业系统管理、网络营销。轻洽网络倡导专心专业,专业人做专业事;专业人员把全部的精力放在一件事情上做细、做深、做精。












定价方案
推荐配合营销管理系统解决方案使用,也可单独购买。
网站模板
根据现有模板进行二次开发
¥298.00/起
- 高效快捷,省时省钱
- 简单易用,品牌展示
小程序定制
满足客户定制化需求
¥3680.00/起
- 高度定制化开发
- 支持多种定制形式
定制系统
多人共用大型系统
¥24900.00/起
- 满足多人同时使用
- 实现权限分配,快捷高效管理
加盟陪跑
团队闭环系统运用
¥66666.00/起
- 加盟代理,共创模式
- 全自动一体化,价值共享
客户评价
爱岗敬业,求实创新,用心服务,勇争一流

南京刘总 5星好评
技术一流,响应迅速,很快就帮我的系统上线了,衷心感谢!

常州谢总 5星好评
技术过硬,解决了技术难题,给了很多宝贵意见,谢谢刘总!

武汉周总 5星好评
服务太对很好,帮我们解决了不少问题!

武汉刘总 5星好评
感谢刘总,同姓氏,很快就上线了,帮到了我,非常感谢!
企业资质
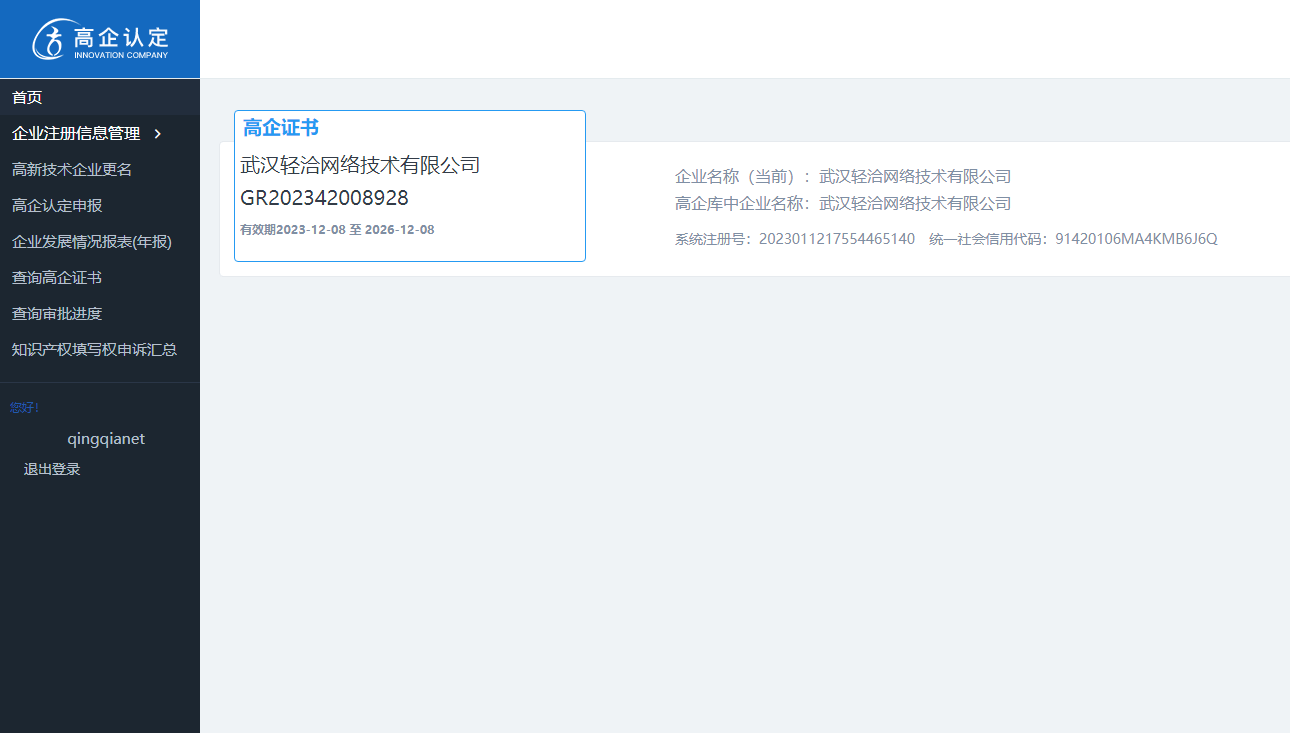
拥有自主研发软件著作权97+,公司获得了ISO9001、ISO20000、ISO20007、3A级信用等级认定、三软企业认定、高新技术企业认定、科技型中小型企业认定和创新型中小企业认定,评为优秀企业,为行业技术发展做出杰出贡献。







技术资讯
聚焦中外高新技术前沿动态
[{{item.columnName}}]{{item.title}}
{{item.time_create == null ? "" : item.time_create.substring(0,10)}}
[{{item.columnName}}]{{item.title}}
{{item.time_create == null ? "" : item.time_create.substring(0,10)}}
[{{item.columnName}}]{{item.title}}
{{item.time_create == null ? "" : item.time_create.substring(0,10)}}